Big data – Hadoop i przetwarzanie petabajtów w analityce predykcyjnej biznesowej
W erze cyfrowej dane stały się paliwem napędzającym nowoczesne przedsiębiorstwa. Big data to nie tylko ogromne zbiory informacji, ale przede wszystkim narzędzie do przewidywania przyszłości i podejmowania świadomych decyzji. Hadoop, otwarty w 2006 roku, zrewolucjonizował sposób, w jaki firmy radzą sobie z przetwarzaniem petabajtów danych. Dzięki niemu analityka predykcyjna w biznesie przeszła od prostych raportów do zaawansowanych prognoz rynkowych, opartych na transakcjach i zachowaniach klientów. Ten artykuł zgłębia, jak Hadoop umożliwia analizę masowych zbiorów danych, prognozując trendy i zmieniając decyzje CEO na w pełni data-driven.
Historia powstania Hadoopu – od inspiracji do otwartego oprogramowania
Hadoop narodził się z potrzeby radzenia sobie z eksplozją danych w internecie. W 2003 roku inżynierowie Google opublikowali artykuł na temat Google File System (GFS), systemu rozproszonego do przechowywania ogromnych ilości danych. To zainspirowało Douglasa Cuttinga i Mike’a Cafarella, którzy pracowali nad projektem Nutch – wyszukiwarką open-source. W 2006 roku Cutting oddzielił od Nutcha komponenty do przechowywania i przetwarzania danych, tworząc Hadoop. Nazwa pochodzi od zabawnego incydentu: syn Cuttinga nazwał swojego pluszowego słonia Hadoopem.
Projekt szybko zyskał popularność dzięki licencji Apache Software Foundation, co pozwoliło na darmowe użycie i rozwój przez społeczność. W tym samym roku Yahoo! zatrudniło Cuttinga, by wykorzystać Hadoop do indeksowania miliardów stron internetowych. Do 2008 roku Hadoop stał się kluczowym elementem ekosystemu big data, umożliwiając firmom takim jak Facebook czy eBay analizę terabajtów danych dziennie. Otwartość kodu źródłowego sprawiła, że narzędzie ewoluowało, integrując się z innymi technologiami, takimi jak Apache Spark czy Hive.
Dziś Hadoop to nie pojedyncze narzędzie, ale framework obejmujący Hadoop Distributed File System (HDFS) do przechowywania i MapReduce do przetwarzania. Jego rozwój odzwierciedla ewolucję big data: od prostego składowania plików do złożonych algorytmów uczenia maszynowego.
Jak działa Hadoop – mechanizmy przetwarzania petabajtów danych
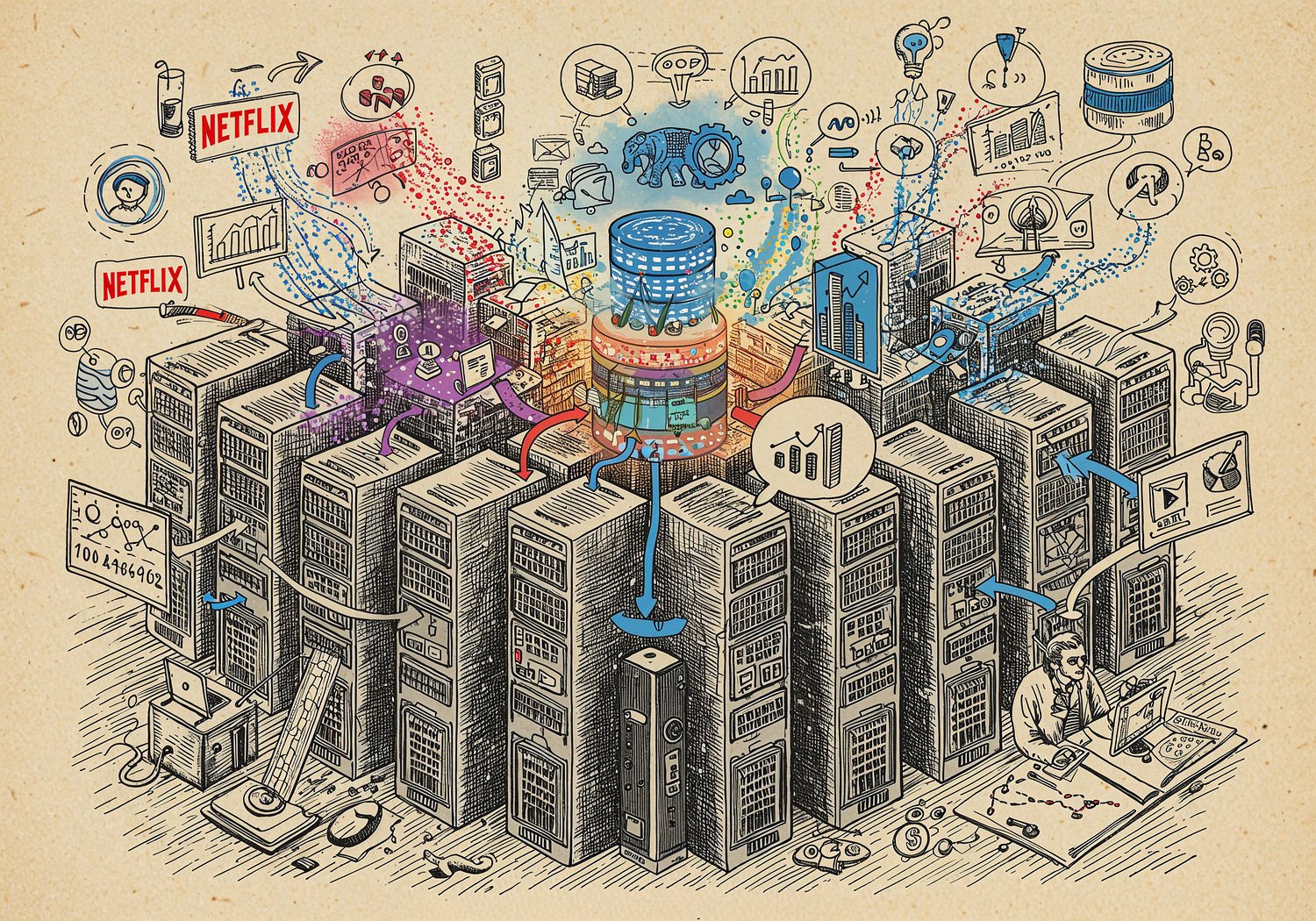
Hadoop wyróżnia się zdolnością do skalowalnego przetwarzania petabajtów – czyli milionów gigabajtów – danych na klastrach tanich serwerów. Kluczowym elementem jest HDFS, system plików rozproszony, który dzieli duże pliki na bloki o rozmiarze 128 MB lub 256 MB. Każdy blok replikuje się na kilku węzłach klastra, zapewniając odporność na awarie. Na przykład, jeśli jeden serwer padnie, dane nie giną, bo kopie istnieją gdzie indziej.
Przetwarzanie odbywa się za pomocą modelu MapReduce, inspirowanego algorytmem MapReduce z Google. Proces dzieli się na dwie fazy: Map i Reduce. W fazie Map dane wejściowe są dzielone na mniejsze porcje, a funkcja mapująca przetwarza je równolegle na różnych węzłach, generując pary klucz-wartość. Następnie faza Reduce agreguje te wyniki, sortując i podsumowując dane. To pozwala na efektywne analizowanie transakcji finansowych czy logów serwerów bez przenoszenia petabajtów po sieci – dane przetwarzane są lokalnie, gdzie są przechowywane.
Hadoop radzi sobie z danymi nieustrukturyzowanymi, takimi jak e-maile, wideo czy sensory IoT, co jest kluczowe w biznesie. Na klastrze z tysiącami węzłów może przetwarzać biliony rekordów w godzinach, co kiedyś zajmowało miesiące na tradycyjnych systemach. Integracja z narzędziami jak YARN (Yet Another Resource Negotiator) pozwala na zarządzanie zasobami i uruchamianie wielu zadań jednocześnie, czyniąc Hadoop elastycznym dla analityki predykcyjnej.
Analityka predykcyjna w biznesie – rola Hadoopu w prognozowaniu trendów
Analityka predykcyjna to sztuka przewidywania przyszłych zdarzeń na podstawie danych historycznych. W biznesie oznacza to prognozowanie popytu, ryzyka kredytowego czy churnu klientów. Hadoop umożliwia to na skalę petabajtów, analizując masowe dane z transakcji, mediów społecznościowych i systemów CRM.
Wyobraź sobie sieć handlową z milionami transakcji dziennie. Tradycyjne bazy danych, jak SQL, nie radzą sobie z tym wolumenem. Hadoop przetwarza te dane za pomocą algorytmów uczenia maszynowego, np. regresji liniowej czy drzew decyzyjnych, implementowanych w Mahout – bibliotece ML dla Hadoopu. Dane z transakcji są mapowane na cechy, takie jak częstotliwość zakupów czy lokalizacja, a następnie redukowane do modeli predykcyjnych. Na przykład, system może przewidzieć, że klient z historią zakupów elektroniki w listopadzie zwiększy wydatki o 20% w grudniu, prognozując trendy świąteczne.
W sektorze finansowym Hadoop analizuje petabajty transakcji kartowych, wykrywając oszustwa w czasie rzeczywistym. Modele predykcyjne, trenowane na historycznych danych, obliczają prawdopodobieństwo fraudu na podstawie wzorców, jak nietypowa lokalizacja transakcji. Firmy jak American Express używają Hadoopu do prognozowania trendów rynkowych, analizując dane makroekonomiczne i transakcyjne, co pozwala na szybkie dostosowanie strategii.
Kluczową zaletą jest batch processing – przetwarzanie wsadowe dużych zbiorów, idealne dla predykcji długoterminowych. Dla szybszych analiz integruje się z Apache Spark, który działa in-memory, redukując czas z godzin do minut. To umożliwia CEO podejmowanie decyzji opartych na prognozach, np. optymalizację zapasów w logistyce, gdzie Hadoop przetwarza dane z GPS i transakcji, przewidując opóźnienia dostaw.
Przykłady biznesowe – jak Hadoop zmienia decyzje w korporacjach
Hadoop nie jest abstrakcją – to narzędzie, które realnie wpływa na miliardy dolarów. Weźmy Netflix: platforma przetwarza petabajty danych o oglądalności, używając Hadoopu do budowania modeli rekomendacyjnych. Analityka predykcyjna analizuje transakcje subskrypcji i wzorce oglądania, prognozując churn na poziomie 5-10%. Dzięki temu Netflix dostosowuje treści, zwiększając retencję o 20-30%, co bezpośrednio wpływa na decyzje CEO o inwestycjach w produkcje.
W branży detalicznej Walmart wykorzystuje Hadoop do analizy 2,5 petabajta danych tygodniowo z transakcji i lojalnościowych programów. System predykcyjny prognozuje trendy zakupowe, np. wzrost popytu na mrożonki w upały, optymalizując łańcuch dostaw. To zmieniło decyzje biznesowe z intuicyjnych na data-driven – menedżerowie opierają się na modelach, redukując straty o miliony.
Banki jak JPMorgan Chase stosują Hadoop w analityce ryzyka. Przetwarzając petabajty transakcji i danych zewnętrznych, modele predykcyjne szacują prawdopodobieństwo defaultu kredytów. W 2020 roku, podczas pandemii, takie prognozy pomogły w szybkim dostosowaniu portfela, minimalizując straty. CEO tych firm podkreślają, że Hadoop umożliwił przejście od reaktywnych decyzji do proaktywnych, gdzie dane z transakcji prognozują trendy makro, jak inflacja czy recesja.
Inny przykład to Amazon, gdzie Hadoop wspiera AWS EMR (Elastic MapReduce). Analizuje petabajty logów zakupowych, przewidując trendy e-commerce, co wpływa na personalizację ofert i decyzje o ekspansji rynkowej.
Wpływ na decyzje CEO – era data-driven w biznesie
Przed Hadoopem decyzje biznesowe opierały się na intuicji i ograniczonych raportach. Dziś, dzięki przetwarzaniu petabajtów, CEO mają dostęp do prognoz opartych na faktach. Hadoop democratizuje big data – nie potrzeba superkomputerów, wystarczy klaster serwerów za ułamek ceny.
Zmiana jest widoczna w strategiach: firmy jak General Electric integrują Hadoop z Industrial Internet, analizując dane z sensorów maszyn, prognozując awarie i optymalizując produkcję. To redukuje koszty o 10-20% i zwiększa efektywność. CEO, tacy jak Jeff Immelt z GE, publicznie chwalili, jak data-driven podejście, wsparte Hadoopem, przekształciło firmę z produkcyjnej w cyfrową.
Wyzwania istnieją: zarządzanie klastrem wymaga ekspertów, a dane muszą być czyszczone. Jednak korzyści przeważają – prognozy trendów z transakcji pozwalają na szybsze reakcje na rynek, jak w przypadku pandemii, gdzie firmy z Hadoopem szybciej dostosowały się do e-commerce.
Przyszłość Hadoopu w analityce predykcyjnej – ewolucja ku hybrydowym systemom
Hadoop nie stoi w miejscu. Z integracją chmury, jak Hadoop on AWS czy Azure HDInsight, staje się dostępny dla małych firm. Przyszłość to hybrydy z AI: narzędzia jak TensorFlow on Hadoop umożliwiają głębokie uczenie na petabajtach, prognozując złożone trendy, np. zachowania konsumenckie w metawersum.
W biznesie analityka predykcyjna ewoluuje ku real-time, z Hadoopem jako backendem dla strumieniowych danych z Kafka. To pozwoli CEO na decyzje w czasie rzeczywistym, jak dynamiczne ceny w retailu. Mimo konkurencji od Spark czy NoSQL, Hadoop pozostaje fundamentem, przetwarzając petabajty i napędzając data-driven rewolucję.
Podsumowując, od 2006 roku Hadoop zmienił big data z buzzwordu w narzędzie biznesowe, umożliwiając prognozy oparte na transakcjach i trendach. Firmy, które go adoptują, zyskują przewagę konkurencyjną, czyniąc decyzje CEO precyzyjnymi i przyszłościowymi.
Informacja: Artykuł (w szczególności treści i obrazy) powstał w całości lub w części przy udziale sztucznej inteligencji (AI). Niektóre informacje mogą być niepełne lub nieścisłe oraz zawierać błędy i/lub przekłamania. Publikowane treści mają charakter wyłącznie informacyjny i nie stanowią porady w szczególności porady prawnej, medycznej ani finansowej. Artykuły sponsorowane i gościnne są przygotowywane przez zewnętrznych autorów i partnerów. Redakcja nie ponosi odpowiedzialności za aktualność, poprawność ani skutki zastosowania się do przedstawionych informacji. W przypadku decyzji dotyczących zdrowia, prawa lub finansów należy skonsultować się z odpowiednim specjalistą.
Traditional detailed engraving illustration with modern elements, etched lines, high contrast black and white, meticulous cross-hatching to create depth, printed on aged parchment paper of: Traditional detailed engraving illustration with modern elements, etched lines, high contrast black and white, meticulous cross-hatching to create depth, printed on aged parchment paper of: A massive cluster of interconnected servers forming a digital landscape, with streams of colorful data particles representing petabytes of information flowing into a central Hadoop elephant icon, where the data is processed through glowing MapReduce gears and HDFS blocks, emerging as predictive charts, graphs, and trend lines forecasting business metrics like sales spikes, fraud alerts, and customer behaviors, surrounded by icons of companies such as Netflix, Walmart, and Amazon, with a CEO figure at a dashboard viewing data-driven insights and future projections. Illustration: copperplate etching texture, ink lines, dramatic shading, artistic style, deep focus, museum quality print with humorous twist. Illustration: copperplate etching texture, ink lines, dramatic shading, artistic style, deep focus, museum quality print with humorous twist.
Polecamy: Technologie IT – od liczydła do komputerów